搜索到
22
篇与
Go
的结果
-
![Golang的特性十(error错误处理)----从基础到优雅实践]() Golang的特性十(error错误处理)----从基础到优雅实践 错误处理是 Go 语言的核心设计哲学之一。与传统的 try-catch 异常机制不同,Go 采用显式错误检查,强调开发者主动处理可能的失败路径。这种设计虽然提高了代码的可控性,但也对开发者提出了更高的要求。本文将深入探讨 Go 的错误处理模式,并提供实用代码示例。一、Go 错误处理基础错误是什么?在 Go 中,错误是一个实现了 error 接口的值:type error interface { Error() string }任何实现了 Error() string 方法的类型都可以作为错误返回。创建错误基础方式:// 使用 errors.New import "errors" err := errors.New("文件未找到") // 使用 fmt.Errorf(格式化错误) file := "config.yaml" err := fmt.Errorf("文件 %s 不存在", file)带错误类型的高级方式(自定义错误):type NotFoundError struct { File string Line int } func (e *NotFoundError) Error() string { return fmt.Sprintf("%s:%d - 未找到", e.File, e.Line) } // 使用 err := &NotFoundError{"config.go", 42}二、错误处理模式经典检查:if err != nilfunc ReadFile(path string) ([]byte, error) { data, err := os.ReadFile(path) if err != nil { return nil, err // 向上传递原始错误 } return data, nil } // 调用方处理 content, err := ReadFile("config.yaml") if err != nil { log.Printf("读取文件失败: %v", err) return }错误断言(类型判断)if nfErr, ok := err.(*NotFoundError); ok { // 处理特定错误类型 log.Printf("文件未找到: %s", nfErr.File) } else if os.IsNotExist(err) { // 使用标准库工具函数 log.Print("系统级文件不存在错误") } else { // 通用错误处理 }三、Go 1.13+ 错误增强错误包装(Error Wrapping)使用 %w 占位符为错误添加上下文:func ReadConfig() error { _, err := os.ReadFile("config.yaml") if err != nil { return fmt.Errorf("读取配置文件失败: %w", err) } return nil }错误链解包使用 errors.Is 和 errors.As 处理包装后的错误:err := ReadConfig() // 检查错误链中是否包含特定类型 var pathError *os.PathError if errors.As(err, &pathError) { fmt.Println("底层 PathError:", pathError.Path) } // 检查错误链中是否包含特定值 if errors.Is(err, os.ErrNotExist) { fmt.Println("文件确实不存在") }四、最佳实践指南 何时返回错误?当函数无法完成其承诺的操作时遇到不可恢复的外部依赖问题(如网络中断)接收到非法参数输入错误处理原则 要做的:添加上下文:使用 fmt.Errorf("operation failed: %w", err) 丰富错误信息处理或返回:每个错误应该被处理或明确返回给上层定义哨兵错误:对重要错误定义可导出的变量:var ErrInvalidInput = errors.New("invalid input")避免的:忽略错误:data, _ = os.ReadFile("file") // 危险!过度使用 panic:if err != nil { panic(err) // 仅在不可恢复时使用 }暴露底层细节:return fmt.Errorf("数据库错误: %v", err) // 可能泄露敏感信息五、实战示例:分层错误处理 场景:Web 服务中的错误传递// 数据层错误 type DatabaseError struct { Query string Err error } func (e *DatabaseError) Error() string { return fmt.Sprintf("查询 %s 失败: %v", e.Query, e.Err) } // 业务逻辑层 func GetUser(id int) (*User, error) { user, err := db.QueryUser(id) if err != nil { return nil, &DatabaseError{ Query: fmt.Sprintf("SELECT * FROM users WHERE id = %d", id), Err: err, } } return user, nil } // 控制器层 func UserHandler(w http.ResponseWriter, r *http.Request) { user, err := GetUser(123) if err != nil { var dbErr *DatabaseError if errors.As(err, &dbErr) { http.Error(w, "数据库错误", http.StatusInternalServerError) log.Printf("数据库错误详情: %+v", dbErr) // 记录完整信息 } else { http.Error(w, err.Error(), http.StatusBadRequest) } return } json.NewEncoder(w).Encode(user) }六、错误日志记录技巧 结构化日志import "go.uber.org/zap" logger, _ := zap.NewProduction() func HandleRequest() { err := processRequest() if err != nil { logger.Error("请求处理失败", zap.Error(err), // 记录错误对象 zap.String("path", "/api"), // 添加上下文 zap.Int("status", 500), ) } }堆栈跟踪记录使用第三方库增强错误信息:import "github.com/pkg/errors" func ReadConfig() error { _, err := os.ReadFile("config.yaml") if err != nil { return errors.Wrap(err, "读取配置文件失败") } return nil } // 记录错误时打印堆栈 fmt.Printf("%+v\n", err)七、panic 与 recover 使用准则:panic:仅用于无法恢复的严重错误(如启动配置缺失)recover:在顶层函数(如 HTTP 中间件)中使用示例:Web 服务恢复中间件func RecoveryMiddleware(next http.Handler) http.Handler { return http.HandlerFunc(func(w http.ResponseWriter, r *http.Request) { defer func() { if err := recover(); err != nil { log.Printf("Recovered from panic: %v", err) http.Error(w, "服务器内部错误", http.StatusInternalServerError) } }() next.ServeHTTP(w, r) }) }
Golang的特性十(error错误处理)----从基础到优雅实践 错误处理是 Go 语言的核心设计哲学之一。与传统的 try-catch 异常机制不同,Go 采用显式错误检查,强调开发者主动处理可能的失败路径。这种设计虽然提高了代码的可控性,但也对开发者提出了更高的要求。本文将深入探讨 Go 的错误处理模式,并提供实用代码示例。一、Go 错误处理基础错误是什么?在 Go 中,错误是一个实现了 error 接口的值:type error interface { Error() string }任何实现了 Error() string 方法的类型都可以作为错误返回。创建错误基础方式:// 使用 errors.New import "errors" err := errors.New("文件未找到") // 使用 fmt.Errorf(格式化错误) file := "config.yaml" err := fmt.Errorf("文件 %s 不存在", file)带错误类型的高级方式(自定义错误):type NotFoundError struct { File string Line int } func (e *NotFoundError) Error() string { return fmt.Sprintf("%s:%d - 未找到", e.File, e.Line) } // 使用 err := &NotFoundError{"config.go", 42}二、错误处理模式经典检查:if err != nilfunc ReadFile(path string) ([]byte, error) { data, err := os.ReadFile(path) if err != nil { return nil, err // 向上传递原始错误 } return data, nil } // 调用方处理 content, err := ReadFile("config.yaml") if err != nil { log.Printf("读取文件失败: %v", err) return }错误断言(类型判断)if nfErr, ok := err.(*NotFoundError); ok { // 处理特定错误类型 log.Printf("文件未找到: %s", nfErr.File) } else if os.IsNotExist(err) { // 使用标准库工具函数 log.Print("系统级文件不存在错误") } else { // 通用错误处理 }三、Go 1.13+ 错误增强错误包装(Error Wrapping)使用 %w 占位符为错误添加上下文:func ReadConfig() error { _, err := os.ReadFile("config.yaml") if err != nil { return fmt.Errorf("读取配置文件失败: %w", err) } return nil }错误链解包使用 errors.Is 和 errors.As 处理包装后的错误:err := ReadConfig() // 检查错误链中是否包含特定类型 var pathError *os.PathError if errors.As(err, &pathError) { fmt.Println("底层 PathError:", pathError.Path) } // 检查错误链中是否包含特定值 if errors.Is(err, os.ErrNotExist) { fmt.Println("文件确实不存在") }四、最佳实践指南 何时返回错误?当函数无法完成其承诺的操作时遇到不可恢复的外部依赖问题(如网络中断)接收到非法参数输入错误处理原则 要做的:添加上下文:使用 fmt.Errorf("operation failed: %w", err) 丰富错误信息处理或返回:每个错误应该被处理或明确返回给上层定义哨兵错误:对重要错误定义可导出的变量:var ErrInvalidInput = errors.New("invalid input")避免的:忽略错误:data, _ = os.ReadFile("file") // 危险!过度使用 panic:if err != nil { panic(err) // 仅在不可恢复时使用 }暴露底层细节:return fmt.Errorf("数据库错误: %v", err) // 可能泄露敏感信息五、实战示例:分层错误处理 场景:Web 服务中的错误传递// 数据层错误 type DatabaseError struct { Query string Err error } func (e *DatabaseError) Error() string { return fmt.Sprintf("查询 %s 失败: %v", e.Query, e.Err) } // 业务逻辑层 func GetUser(id int) (*User, error) { user, err := db.QueryUser(id) if err != nil { return nil, &DatabaseError{ Query: fmt.Sprintf("SELECT * FROM users WHERE id = %d", id), Err: err, } } return user, nil } // 控制器层 func UserHandler(w http.ResponseWriter, r *http.Request) { user, err := GetUser(123) if err != nil { var dbErr *DatabaseError if errors.As(err, &dbErr) { http.Error(w, "数据库错误", http.StatusInternalServerError) log.Printf("数据库错误详情: %+v", dbErr) // 记录完整信息 } else { http.Error(w, err.Error(), http.StatusBadRequest) } return } json.NewEncoder(w).Encode(user) }六、错误日志记录技巧 结构化日志import "go.uber.org/zap" logger, _ := zap.NewProduction() func HandleRequest() { err := processRequest() if err != nil { logger.Error("请求处理失败", zap.Error(err), // 记录错误对象 zap.String("path", "/api"), // 添加上下文 zap.Int("status", 500), ) } }堆栈跟踪记录使用第三方库增强错误信息:import "github.com/pkg/errors" func ReadConfig() error { _, err := os.ReadFile("config.yaml") if err != nil { return errors.Wrap(err, "读取配置文件失败") } return nil } // 记录错误时打印堆栈 fmt.Printf("%+v\n", err)七、panic 与 recover 使用准则:panic:仅用于无法恢复的严重错误(如启动配置缺失)recover:在顶层函数(如 HTTP 中间件)中使用示例:Web 服务恢复中间件func RecoveryMiddleware(next http.Handler) http.Handler { return http.HandlerFunc(func(w http.ResponseWriter, r *http.Request) { defer func() { if err := recover(); err != nil { log.Printf("Recovered from panic: %v", err) http.Error(w, "服务器内部错误", http.StatusInternalServerError) } }() next.ServeHTTP(w, r) }) } -
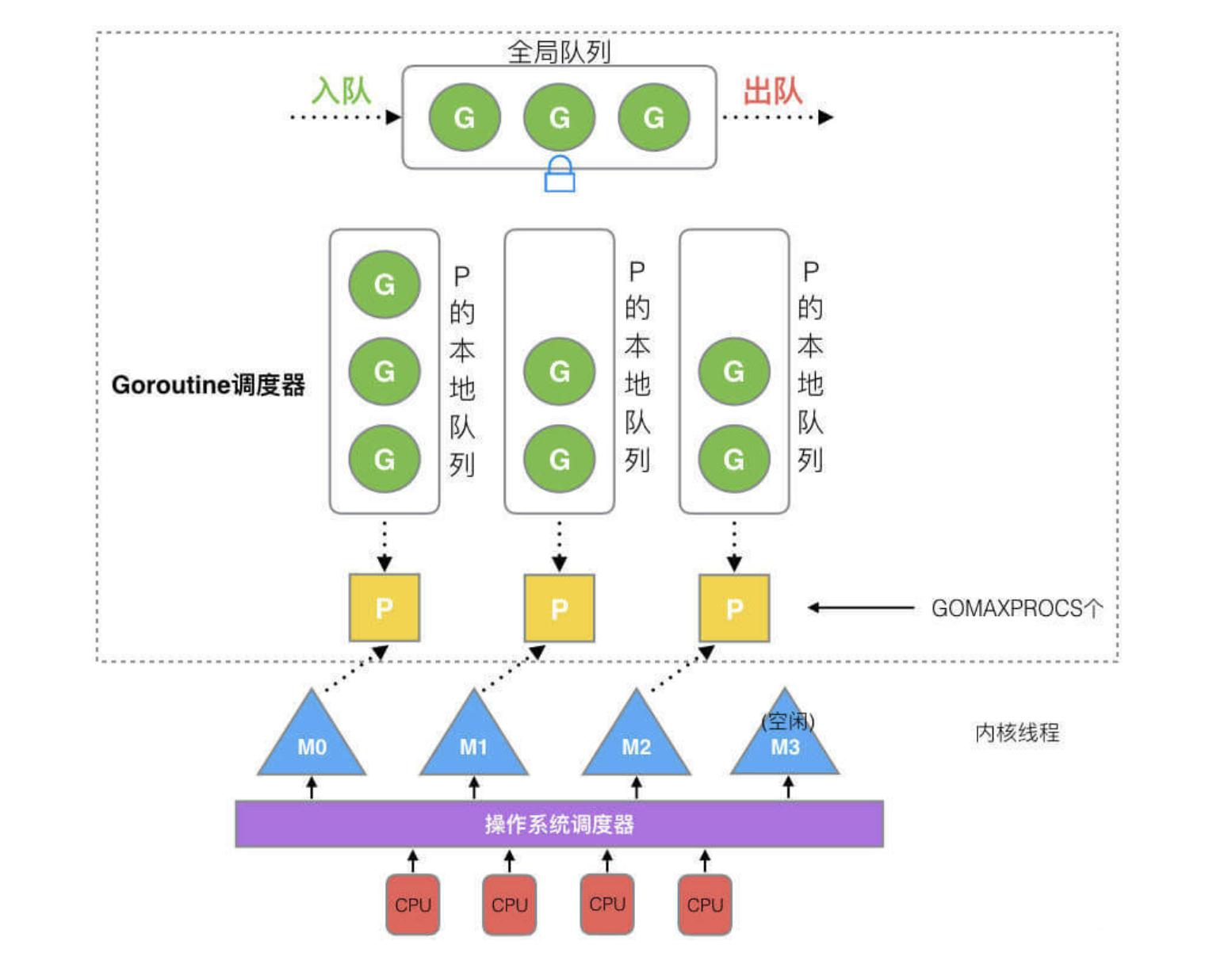
![Golang的特性九(GMP调度模型)----高并发的核心机制]() Golang的特性九(GMP调度模型)----高并发的核心机制 1. 协程由来 进程通常表示计算机中正在运行的程序实例。线程通常表示内核级的线程。计算机中最小可执行单元协程线程分为内核级线程和用户级线程,一个或多个用户级线程要绑定一个内核级线程,其中内核级线程依然叫线程(thread),而用户级线程叫协程(co-routine)。协程跟线程是有区别的,线程由 CPU 调度是抢占式的,协程由用户态调度是协作式的,一个协程让出 CPU 后,才执行下一个协程,在go语言中,协程叫做goroutine,一个goroutine初始只占几KB,但实际是可伸缩的,如果需要更多内容,runtime 会自动为 goroutine 分配,因此调度起来非常方便,支持大量的goroutine2. 什么是GMP模型? GMP模型是Go语言并发模型的核心,它由三个主要组件组成:G(Goroutine):Goroutine是Go语言中的轻量级线程,由Go运行时管理。Goroutine的创建和销毁成本很低,可以轻松创建成千上万个Goroutine。M(Machine):M代表操作系统线程(OS Thread),由操作系统管理。M负责执行Goroutine的代码。P(Processor):P是Go运行时抽象出来的处理器,它负责调度Goroutine到M上执行。P的数量通常等于CPU核心数,可以通过GOMAXPROCS环境变量来设置。3. GMP模型的工作原理Goroutine的创建:当创建一个Goroutine时,它会被放入一个全局队列或本地队列中,等待被调度执行。调度器:Go运行时调度器会从队列中取出Goroutine,并将其分配给一个P。执行:P会将Goroutine绑定到一个M上,M是操作系统线程,负责执行Goroutine的代码。上下文切换:当一个Goroutine阻塞(如等待I/O操作)时,调度器会将其从M上解绑,并调度另一个Goroutine到该M上执行。负载均衡:调度器会确保所有的P都尽可能均匀地分配Goroutine,以实现负载均衡。下面通过一个简单的代码示例来演示GMP模型的工作原理。package main import ( "fmt" "runtime" "sync" "time" ) func main() { // 设置使用的CPU核心数 runtime.GOMAXPROCS(2) var wg sync.WaitGroup // 创建10个Goroutine for i := 0; i < 10; i++ { wg.Add(1) go func(id int) { defer wg.Done() fmt.Printf("Goroutine %d started\n", id) time.Sleep(time.Second) // 模拟耗时操作 fmt.Printf("Goroutine %d finished\n", id) }(i) } // 等待所有Goroutine完成 wg.Wait() fmt.Println("All Goroutines finished") }代码解析设置CPU核心数:通过runtime.GOMAXPROCS(2)设置使用的CPU核心数为2,这意味着最多有2个P(Processor)在调度Goroutine。创建Goroutine:使用go关键字创建10个Goroutine,每个Goroutine都会打印开始和结束的信息,并模拟一个耗时操作(time.Sleep)。WaitGroup:使用sync.WaitGroup来等待所有Goroutine完成。输出结果:运行程序后,你会看到10个Goroutine被调度执行,但由于我们设置了2个CPU核心,所以最多只有2个Goroutine在同时执行。P的数量和M的数量的确定P的数量:由启动时环境变量GOMAXPROCS来决定的,一般设置GOMAXPROCS也不会超过系统的核数M的数量:go程序启动时,会设置M的最大数量,默认10000。但是内核很难创建出如此多的线程,因此默认情况下M的最大数量取决于内核
Golang的特性九(GMP调度模型)----高并发的核心机制 1. 协程由来 进程通常表示计算机中正在运行的程序实例。线程通常表示内核级的线程。计算机中最小可执行单元协程线程分为内核级线程和用户级线程,一个或多个用户级线程要绑定一个内核级线程,其中内核级线程依然叫线程(thread),而用户级线程叫协程(co-routine)。协程跟线程是有区别的,线程由 CPU 调度是抢占式的,协程由用户态调度是协作式的,一个协程让出 CPU 后,才执行下一个协程,在go语言中,协程叫做goroutine,一个goroutine初始只占几KB,但实际是可伸缩的,如果需要更多内容,runtime 会自动为 goroutine 分配,因此调度起来非常方便,支持大量的goroutine2. 什么是GMP模型? GMP模型是Go语言并发模型的核心,它由三个主要组件组成:G(Goroutine):Goroutine是Go语言中的轻量级线程,由Go运行时管理。Goroutine的创建和销毁成本很低,可以轻松创建成千上万个Goroutine。M(Machine):M代表操作系统线程(OS Thread),由操作系统管理。M负责执行Goroutine的代码。P(Processor):P是Go运行时抽象出来的处理器,它负责调度Goroutine到M上执行。P的数量通常等于CPU核心数,可以通过GOMAXPROCS环境变量来设置。3. GMP模型的工作原理Goroutine的创建:当创建一个Goroutine时,它会被放入一个全局队列或本地队列中,等待被调度执行。调度器:Go运行时调度器会从队列中取出Goroutine,并将其分配给一个P。执行:P会将Goroutine绑定到一个M上,M是操作系统线程,负责执行Goroutine的代码。上下文切换:当一个Goroutine阻塞(如等待I/O操作)时,调度器会将其从M上解绑,并调度另一个Goroutine到该M上执行。负载均衡:调度器会确保所有的P都尽可能均匀地分配Goroutine,以实现负载均衡。下面通过一个简单的代码示例来演示GMP模型的工作原理。package main import ( "fmt" "runtime" "sync" "time" ) func main() { // 设置使用的CPU核心数 runtime.GOMAXPROCS(2) var wg sync.WaitGroup // 创建10个Goroutine for i := 0; i < 10; i++ { wg.Add(1) go func(id int) { defer wg.Done() fmt.Printf("Goroutine %d started\n", id) time.Sleep(time.Second) // 模拟耗时操作 fmt.Printf("Goroutine %d finished\n", id) }(i) } // 等待所有Goroutine完成 wg.Wait() fmt.Println("All Goroutines finished") }代码解析设置CPU核心数:通过runtime.GOMAXPROCS(2)设置使用的CPU核心数为2,这意味着最多有2个P(Processor)在调度Goroutine。创建Goroutine:使用go关键字创建10个Goroutine,每个Goroutine都会打印开始和结束的信息,并模拟一个耗时操作(time.Sleep)。WaitGroup:使用sync.WaitGroup来等待所有Goroutine完成。输出结果:运行程序后,你会看到10个Goroutine被调度执行,但由于我们设置了2个CPU核心,所以最多只有2个Goroutine在同时执行。P的数量和M的数量的确定P的数量:由启动时环境变量GOMAXPROCS来决定的,一般设置GOMAXPROCS也不会超过系统的核数M的数量:go程序启动时,会设置M的最大数量,默认10000。但是内核很难创建出如此多的线程,因此默认情况下M的最大数量取决于内核 -
![Golang的特性八(reflect反射)----解锁代码的无限可能]() Golang的特性八(reflect反射)----解锁代码的无限可能 1. 反射反射是指在程序运行期间对程序本身进行访问和修改的能力。正常情况程序在编译时,变量被转换为内存地址,变量名不会被编译器写入到可执行部分。在运行程序时,程序无法获取自身的信息。支持反射的语言可以在程序编译期将变量的反射信息,如字段名称、类型信息、结构体信息等整合到可执行文件中,并给程序提供接口访问反射信息,这样就可以在程序运行期获取类型的反射信息,并且有能力修改它们2. 反射可以做什么? 1)反射可以在运行时动态获取变量的各种信息,比如变量的类型,类别等信息2)如果是结构体变量,还可以获取到结构体本身的信息(包括结构体的字段、方法)3)通过反射,可以修改变量的值,可以调用关联的方法。4)使用反射,需要import "reflect"3. 反射相关的函数reflect.TypeOf(变量名),获取变量的类型,返回reflect.Type类型reflect.ValueOf(变量名),获取变量的值,返回reflect.Value类型4. 反射的基本操作 获取类型信息我们可以使用 reflect.TypeOf() 函数获取任意值的类型信息:package main import ( "fmt" "reflect" ) func main() { var x int = 42 t := reflect.TypeOf(x) fmt.Println(t) // 输出: int }获取值信息我们可以使用 reflect.ValueOf() 函数获取任意值的 Value 对象:package main import ( "fmt" "reflect" ) func main() { var x int = 42 v := reflect.ValueOf(x) fmt.Println(v) // 输出: 42 }操作值通过 Value 对象,我们可以获取和修改值的实际数据:package main import ( "fmt" "reflect" ) func main() { var x int = 42 v := reflect.ValueOf(&x).Elem() // 获取 x 的地址,并通过 Elem() 获取指向的值 v.SetInt(100) // 修改 x 的值 fmt.Println(x) // 输出: 100 }5. 反射的应用场景 反射在 Golang 中有着广泛的应用场景,例如:序列化和反序列化: 将结构体转换为 JSON、XML 等格式,或者从这些格式中解析出结构体。package main import ( "encoding/json" "fmt" "reflect" ) type Person struct { Name string `json:"name"` Age int `json:"age"` } func main() { // 序列化 p := Person{Name: "Alice", Age: 25} jsonData, _ := json.Marshal(p) fmt.Println(string(jsonData)) // 输出: {"name":"Alice","age":25} // 反序列化 var p2 Person json.Unmarshal(jsonData, &p2) fmt.Println(p2) // 输出: {Alice 25} // 使用反射检查结构体字段 v := reflect.ValueOf(p2) for i := 0; i < v.NumField(); i++ { field := v.Field(i) fmt.Printf("Field %d: %v\n", i, field.Interface()) } }ORM 框架: 将数据库记录映射到结构体,或者将结构体保存到数据库。package main import ( "fmt" "reflect" ) type User struct { ID int Name string Age int } // 模拟数据库查询结果 func mockDBQuery() map[string]interface{} { return map[string]interface{}{ "ID": 1, "Name": "Bob", "Age": 30, } } func main() { // 模拟从数据库查询一条记录 dbRecord := mockDBQuery() // 创建目标结构体 var user User v := reflect.ValueOf(&user).Elem() // 动态填充结构体字段 for key, value := range dbRecord { field := v.FieldByName(key) if field.IsValid() && field.CanSet() { field.Set(reflect.ValueOf(value)) } } fmt.Println(user) // 输出: {1 Bob 30} }动态调用函数: 根据函数名和参数动态调用函数。package main import ( "fmt" "reflect" ) func Greet(name string) { fmt.Printf("Hello, %s!\n", name) } func Add(a, b int) int { return a + b } func main() { // 动态调用 Greet 函数 greetFunc := reflect.ValueOf(Greet) args := []reflect.Value{reflect.ValueOf("Alice")} greetFunc.Call(args) // 输出: Hello, Alice! // 动态调用 Add 函数 addFunc := reflect.ValueOf(Add) args = []reflect.Value{reflect.ValueOf(10), reflect.ValueOf(20)} result := addFunc.Call(args) fmt.Println(result[0].Int()) // 输出: 30 }编写通用代码: 例如编写可以处理任意类型数据的函数。package main import ( "fmt" "reflect" ) func PrintStructFields(s interface{}) { v := reflect.ValueOf(s) if v.Kind() == reflect.Ptr { v = v.Elem() } t := v.Type() for i := 0; i < v.NumField(); i++ { field := v.Field(i) fieldName := t.Field(i).Name fmt.Printf("%s: %v\n", fieldName, field.Interface()) } } type Book struct { Title string Author string Pages int } func main() { book := Book{Title: "The Go Programming Language", Author: "Alan A. A. Donovan", Pages: 380} PrintStructFields(&book) // 输出: // Title: The Go Programming Language // Author: Alan A. A. Donovan // Pages: 380 }6. 常见问题与避免方法 - 问题一:过度使用反射 过度使用反射可能导致代码难以理解和维护,降低性能。避免方法:只有在确实需要动态操作类型或值时才使用反射,尽量保持代码的静态类型。 - 易错点二:无法进行类型检查 反射不能像常规类型那样进行类型检查,可能导致运行时错误。避免方法:在使用反射前,先通过Kind()方法检查类型,确保安全。 - 易错点三:修改不可导出字段 反射可以访问不可导出字段,但这样做可能导致封装破坏。避免方法:除非必要,否则避免修改不可导出字段,尊重封装原则。需要注意的是,使用Go语言反射可能会带来一定的性能损失,因为反射操作是在运行时进行的,而不是在编译时。因此,在使用反射时需要权衡灵活性和性能。
Golang的特性八(reflect反射)----解锁代码的无限可能 1. 反射反射是指在程序运行期间对程序本身进行访问和修改的能力。正常情况程序在编译时,变量被转换为内存地址,变量名不会被编译器写入到可执行部分。在运行程序时,程序无法获取自身的信息。支持反射的语言可以在程序编译期将变量的反射信息,如字段名称、类型信息、结构体信息等整合到可执行文件中,并给程序提供接口访问反射信息,这样就可以在程序运行期获取类型的反射信息,并且有能力修改它们2. 反射可以做什么? 1)反射可以在运行时动态获取变量的各种信息,比如变量的类型,类别等信息2)如果是结构体变量,还可以获取到结构体本身的信息(包括结构体的字段、方法)3)通过反射,可以修改变量的值,可以调用关联的方法。4)使用反射,需要import "reflect"3. 反射相关的函数reflect.TypeOf(变量名),获取变量的类型,返回reflect.Type类型reflect.ValueOf(变量名),获取变量的值,返回reflect.Value类型4. 反射的基本操作 获取类型信息我们可以使用 reflect.TypeOf() 函数获取任意值的类型信息:package main import ( "fmt" "reflect" ) func main() { var x int = 42 t := reflect.TypeOf(x) fmt.Println(t) // 输出: int }获取值信息我们可以使用 reflect.ValueOf() 函数获取任意值的 Value 对象:package main import ( "fmt" "reflect" ) func main() { var x int = 42 v := reflect.ValueOf(x) fmt.Println(v) // 输出: 42 }操作值通过 Value 对象,我们可以获取和修改值的实际数据:package main import ( "fmt" "reflect" ) func main() { var x int = 42 v := reflect.ValueOf(&x).Elem() // 获取 x 的地址,并通过 Elem() 获取指向的值 v.SetInt(100) // 修改 x 的值 fmt.Println(x) // 输出: 100 }5. 反射的应用场景 反射在 Golang 中有着广泛的应用场景,例如:序列化和反序列化: 将结构体转换为 JSON、XML 等格式,或者从这些格式中解析出结构体。package main import ( "encoding/json" "fmt" "reflect" ) type Person struct { Name string `json:"name"` Age int `json:"age"` } func main() { // 序列化 p := Person{Name: "Alice", Age: 25} jsonData, _ := json.Marshal(p) fmt.Println(string(jsonData)) // 输出: {"name":"Alice","age":25} // 反序列化 var p2 Person json.Unmarshal(jsonData, &p2) fmt.Println(p2) // 输出: {Alice 25} // 使用反射检查结构体字段 v := reflect.ValueOf(p2) for i := 0; i < v.NumField(); i++ { field := v.Field(i) fmt.Printf("Field %d: %v\n", i, field.Interface()) } }ORM 框架: 将数据库记录映射到结构体,或者将结构体保存到数据库。package main import ( "fmt" "reflect" ) type User struct { ID int Name string Age int } // 模拟数据库查询结果 func mockDBQuery() map[string]interface{} { return map[string]interface{}{ "ID": 1, "Name": "Bob", "Age": 30, } } func main() { // 模拟从数据库查询一条记录 dbRecord := mockDBQuery() // 创建目标结构体 var user User v := reflect.ValueOf(&user).Elem() // 动态填充结构体字段 for key, value := range dbRecord { field := v.FieldByName(key) if field.IsValid() && field.CanSet() { field.Set(reflect.ValueOf(value)) } } fmt.Println(user) // 输出: {1 Bob 30} }动态调用函数: 根据函数名和参数动态调用函数。package main import ( "fmt" "reflect" ) func Greet(name string) { fmt.Printf("Hello, %s!\n", name) } func Add(a, b int) int { return a + b } func main() { // 动态调用 Greet 函数 greetFunc := reflect.ValueOf(Greet) args := []reflect.Value{reflect.ValueOf("Alice")} greetFunc.Call(args) // 输出: Hello, Alice! // 动态调用 Add 函数 addFunc := reflect.ValueOf(Add) args = []reflect.Value{reflect.ValueOf(10), reflect.ValueOf(20)} result := addFunc.Call(args) fmt.Println(result[0].Int()) // 输出: 30 }编写通用代码: 例如编写可以处理任意类型数据的函数。package main import ( "fmt" "reflect" ) func PrintStructFields(s interface{}) { v := reflect.ValueOf(s) if v.Kind() == reflect.Ptr { v = v.Elem() } t := v.Type() for i := 0; i < v.NumField(); i++ { field := v.Field(i) fieldName := t.Field(i).Name fmt.Printf("%s: %v\n", fieldName, field.Interface()) } } type Book struct { Title string Author string Pages int } func main() { book := Book{Title: "The Go Programming Language", Author: "Alan A. A. Donovan", Pages: 380} PrintStructFields(&book) // 输出: // Title: The Go Programming Language // Author: Alan A. A. Donovan // Pages: 380 }6. 常见问题与避免方法 - 问题一:过度使用反射 过度使用反射可能导致代码难以理解和维护,降低性能。避免方法:只有在确实需要动态操作类型或值时才使用反射,尽量保持代码的静态类型。 - 易错点二:无法进行类型检查 反射不能像常规类型那样进行类型检查,可能导致运行时错误。避免方法:在使用反射前,先通过Kind()方法检查类型,确保安全。 - 易错点三:修改不可导出字段 反射可以访问不可导出字段,但这样做可能导致封装破坏。避免方法:除非必要,否则避免修改不可导出字段,尊重封装原则。需要注意的是,使用Go语言反射可能会带来一定的性能损失,因为反射操作是在运行时进行的,而不是在编译时。因此,在使用反射时需要权衡灵活性和性能。 -
![Golang的特性七(interface接口)----面向对象编程的利器]() Golang的特性七(interface接口)----面向对象编程的利器 Go 语言虽然不像传统面向对象语言那样拥有类和继承的概念,但它通过接口(interface)提供了一种灵活的方式来实现面向对象编程。本文将深入探讨 Go 语言接口,并结合代码示例,帮助你理解接口的定义、实现、使用以及它在面向对象编程中的应用。一.接口的定义 Go语言中的接口(interface)是一组方法签名的集合,是一种抽象类型。接口定义了方法,但没有实现,而是由具体的类型(struct)实现这些方法,因此接口是一种实现多态的机制。Go语言中的接口定义语法如下:type Animal interface { Say() string Name() string }二. 接口的实现 如果一个类型需要实现 Animal 接口,那么它只需要实现 Say() string 和 Name() string 方法,下面的 Duck 结构体就是接口的一个实现:type Duck struct { Name string Sound string } func (a *Duck) MySay() string { return fmt.Sprintf("My Sound is: %s", a.Sound) } func (a *Duck) MyName() string { return fmt.Sprintf("My Name is: %s", a.Name) }上述代码根本就没有 Animal 接口的影子,这是为什么呢?Go 语言中接口的实现都是隐式的,我们只需要实现 MySay() string 和 Name() string 方法就实现了 Animal 接口。三.接口的使用func PrintInfo(h Human) { fmt.Println(h.Name()) fmt.Println(h.Say()) } func main() { // 创建 Duck 实例 duck := &Duck{ name: "Donald", say: "Quack", } 上面的代码定义了一个 PrintInfo() 函数,它接受一个 Human 接口类型的参数。我们可以将任何实现了 Human 接口的类型传递给这个函数,例如 Duck 类型。完整代码如下:package main import "fmt" // 定义 Human 接口 type Human interface { Say() string Name() string } // 定义 Duck 结构体 type Duck struct { name string say string } // 实现 Human 接口的 Say 方法 func (d *Duck) Say() string { return fmt.Sprintf("My Sound is: %s", d.say) } // 实现 Human 接口的 Name 方法 func (d *Duck) Name() string { return fmt.Sprintf("My Name is: %s", d.name) } // 定义一个函数,接收 Human 接口类型 func PrintInfo(h Human) { fmt.Println(h.Name()) fmt.Println(h.Say()) } func main() { // 创建 Duck 实例 duck := &Duck{ name: "Donald", say: "Quack", } // 调用 PrintInfo 函数,传入 Duck 实例 PrintInfo(duck) } 上面代码输出:My Name is: DonaldMy Sound is: Quack四.接口与面向对象 虽然 Go 语言没有类和继承的概念,但接口可以实现类似的功能。封装: 接口可以将数据和行为封装在一起,隐藏实现细节。多态: 接口可以实现多态,使代码更加灵活和可扩展。组合: 接口可以通过组合其他接口来实现更复杂的行为。五. 接口的嵌套 Go 语言支持接口的嵌套,可以将多个接口组合成一个新的接口。type Walker interface { Walk() string } type Swimmer interface { Swim() string } type Amphibian interface { Walker Swimmer }上面的代码定义了两个接口 Walker 和 Swimmer,然后将它们组合成一个新的接口 Amphibian。任何实现了 Walker 和 Swimmer 接口的类型都可以被认为是 Amphibian 接口的实现。六.空接口 空接口 interface{} 不包含任何方法,因此任何类型都实现了空接口。空接口可以用来表示任意类型的值。func PrintAnything(v interface{}) { fmt.Println(v) } func main() { PrintAnything(42) // 输出: 42 PrintAnything("Hello") // 输出: Hello }七.类型断言 在Go语言中,可以使用类型断言(type assertion)来判断一个接口实例的底层值是什么类型,并将其转换成对应的类型。类型断言的语法如下:value, ok := interfaceVar.(Type)使用类型断言package main import ( "fmt" ) func main() { var i interface{} i = "hello" // 使用类型断言判断 i 的底层值是否为字符串类型 if s, ok := i.(string); ok { fmt.Printf("i is a string: %s\n", s) } else { fmt.Println("i is not a string") } // 使用类型断言判断 i 的底层值是否为整数类型 if n, ok := i.(int); ok { fmt.Printf("i is an integer: %d\n", n) } else { fmt.Println("i is not an integer") } }八. 指针和结构体接收者 我们经常能看到两种实现接口的接收方式:指针和结构体,看下面缩略代码:type Animal interface { MySay() string MyName() string } type Duck struct {...} //指针方式 func (a *Duck) MySay() string {...} func (a *Duck) MyName() string {...} //结构体方式 func (a Duck) MySay() string {...} func (a Duck) MyName() string {...}因为结构体类型和指针类型是不同的,但是上面两种实现不可以同时存在,Go 语言的编译器会在结构体类型和指针类型都实现一个方法时报错 method redeclared。实现接口的类型和初始化返回的类型两个维度共组成了四种情况,然而这四种情况不是都能通过编译器的检查:表头结构体接收者- func (a Duck) MySay()指针接收者 - func (a *Duck) MySay()结构体指针方式初始化var Duck Animal = &Duck{}通过检查通过检查 结构体方式初始化var Duck Animal = Duck{}通过检查不通过 如上表所示,无论上述代码中初始化的变量 是 Duck{} 还是 &Duck{},使用 MySay() 调用方法时都会发生值拷贝:对于 &Duck{} 来说,这意味着拷贝一个新的 &Duck{} 指针,这个指针与原来的指针指向一个相同并且唯一的结构体,所以编译器可以隐式的对变量解引用(dereference)获取指针指向的结构体;对于 Duck{} 来说,这意味着 MySay 方法会接受一个全新的 Duck{},因为方法的参数是 *Cat,编译器不会无中生有创建一个新的指针;即使编译器可以创建新指针,这个指针指向的也不是最初调用该方法的结构体;总结起来:当我们使用指针实现接口时,只有指针类型的变量才会实现该接口;当我们使用结构体实现接口时,指针类型和结构体类型都会实现该接口。
Golang的特性七(interface接口)----面向对象编程的利器 Go 语言虽然不像传统面向对象语言那样拥有类和继承的概念,但它通过接口(interface)提供了一种灵活的方式来实现面向对象编程。本文将深入探讨 Go 语言接口,并结合代码示例,帮助你理解接口的定义、实现、使用以及它在面向对象编程中的应用。一.接口的定义 Go语言中的接口(interface)是一组方法签名的集合,是一种抽象类型。接口定义了方法,但没有实现,而是由具体的类型(struct)实现这些方法,因此接口是一种实现多态的机制。Go语言中的接口定义语法如下:type Animal interface { Say() string Name() string }二. 接口的实现 如果一个类型需要实现 Animal 接口,那么它只需要实现 Say() string 和 Name() string 方法,下面的 Duck 结构体就是接口的一个实现:type Duck struct { Name string Sound string } func (a *Duck) MySay() string { return fmt.Sprintf("My Sound is: %s", a.Sound) } func (a *Duck) MyName() string { return fmt.Sprintf("My Name is: %s", a.Name) }上述代码根本就没有 Animal 接口的影子,这是为什么呢?Go 语言中接口的实现都是隐式的,我们只需要实现 MySay() string 和 Name() string 方法就实现了 Animal 接口。三.接口的使用func PrintInfo(h Human) { fmt.Println(h.Name()) fmt.Println(h.Say()) } func main() { // 创建 Duck 实例 duck := &Duck{ name: "Donald", say: "Quack", } 上面的代码定义了一个 PrintInfo() 函数,它接受一个 Human 接口类型的参数。我们可以将任何实现了 Human 接口的类型传递给这个函数,例如 Duck 类型。完整代码如下:package main import "fmt" // 定义 Human 接口 type Human interface { Say() string Name() string } // 定义 Duck 结构体 type Duck struct { name string say string } // 实现 Human 接口的 Say 方法 func (d *Duck) Say() string { return fmt.Sprintf("My Sound is: %s", d.say) } // 实现 Human 接口的 Name 方法 func (d *Duck) Name() string { return fmt.Sprintf("My Name is: %s", d.name) } // 定义一个函数,接收 Human 接口类型 func PrintInfo(h Human) { fmt.Println(h.Name()) fmt.Println(h.Say()) } func main() { // 创建 Duck 实例 duck := &Duck{ name: "Donald", say: "Quack", } // 调用 PrintInfo 函数,传入 Duck 实例 PrintInfo(duck) } 上面代码输出:My Name is: DonaldMy Sound is: Quack四.接口与面向对象 虽然 Go 语言没有类和继承的概念,但接口可以实现类似的功能。封装: 接口可以将数据和行为封装在一起,隐藏实现细节。多态: 接口可以实现多态,使代码更加灵活和可扩展。组合: 接口可以通过组合其他接口来实现更复杂的行为。五. 接口的嵌套 Go 语言支持接口的嵌套,可以将多个接口组合成一个新的接口。type Walker interface { Walk() string } type Swimmer interface { Swim() string } type Amphibian interface { Walker Swimmer }上面的代码定义了两个接口 Walker 和 Swimmer,然后将它们组合成一个新的接口 Amphibian。任何实现了 Walker 和 Swimmer 接口的类型都可以被认为是 Amphibian 接口的实现。六.空接口 空接口 interface{} 不包含任何方法,因此任何类型都实现了空接口。空接口可以用来表示任意类型的值。func PrintAnything(v interface{}) { fmt.Println(v) } func main() { PrintAnything(42) // 输出: 42 PrintAnything("Hello") // 输出: Hello }七.类型断言 在Go语言中,可以使用类型断言(type assertion)来判断一个接口实例的底层值是什么类型,并将其转换成对应的类型。类型断言的语法如下:value, ok := interfaceVar.(Type)使用类型断言package main import ( "fmt" ) func main() { var i interface{} i = "hello" // 使用类型断言判断 i 的底层值是否为字符串类型 if s, ok := i.(string); ok { fmt.Printf("i is a string: %s\n", s) } else { fmt.Println("i is not a string") } // 使用类型断言判断 i 的底层值是否为整数类型 if n, ok := i.(int); ok { fmt.Printf("i is an integer: %d\n", n) } else { fmt.Println("i is not an integer") } }八. 指针和结构体接收者 我们经常能看到两种实现接口的接收方式:指针和结构体,看下面缩略代码:type Animal interface { MySay() string MyName() string } type Duck struct {...} //指针方式 func (a *Duck) MySay() string {...} func (a *Duck) MyName() string {...} //结构体方式 func (a Duck) MySay() string {...} func (a Duck) MyName() string {...}因为结构体类型和指针类型是不同的,但是上面两种实现不可以同时存在,Go 语言的编译器会在结构体类型和指针类型都实现一个方法时报错 method redeclared。实现接口的类型和初始化返回的类型两个维度共组成了四种情况,然而这四种情况不是都能通过编译器的检查:表头结构体接收者- func (a Duck) MySay()指针接收者 - func (a *Duck) MySay()结构体指针方式初始化var Duck Animal = &Duck{}通过检查通过检查 结构体方式初始化var Duck Animal = Duck{}通过检查不通过 如上表所示,无论上述代码中初始化的变量 是 Duck{} 还是 &Duck{},使用 MySay() 调用方法时都会发生值拷贝:对于 &Duck{} 来说,这意味着拷贝一个新的 &Duck{} 指针,这个指针与原来的指针指向一个相同并且唯一的结构体,所以编译器可以隐式的对变量解引用(dereference)获取指针指向的结构体;对于 Duck{} 来说,这意味着 MySay 方法会接受一个全新的 Duck{},因为方法的参数是 *Cat,编译器不会无中生有创建一个新的指针;即使编译器可以创建新指针,这个指针指向的也不是最初调用该方法的结构体;总结起来:当我们使用指针实现接口时,只有指针类型的变量才会实现该接口;当我们使用结构体实现接口时,指针类型和结构体类型都会实现该接口。 -
![Golang的特性六(值传递与指针传递)----参数传递机制]() Golang的特性六(值传递与指针传递)----参数传递机制 在 Go 语言开发过程中,我们常常会面临一个抉择:在函数调用时,究竟应该选择值传递还是指针传递?这不仅关乎程序的性能,更影响着数据的安全性和一致性。go允许通过指针(有时称为引用)和值来传递参数。在这篇文章中,我们将比较两种方法,特别注意可能影响选择的不同情境。1. go中的传递本质 在 Go 语言里,只有值传递。所谓的引用传递,实际上也是传值,只不过拷贝的对象是一个地址,这个地址指向了另一个值的存储位置。所以,我们可以将问题转换为:到底该传值还是该传地址?2. 如何选择传递方法是 - 遵循项目规范 项目规范文档是我们的首要依据。如果文档中对函数参数传递方式有明确规定,那么按照文档执行即可。例如,在调用第三方 SDK 时,很多简单类型(如 int、字符串类型等)的参数传递往往遵循特定规范,可能会要求传地址,这背后是为了满足接口设计的一致性和效率需求。- 必须传地址的情况 当需要修改原始数据时,必须传递地址。如果传入值的副本,在函数内部对副本的修改将无法影响到原始数据。例如:package main import "fmt" func modifyValue(ptr *int) { *ptr = 100 } func main() { num := 50 modifyValue(&num) fmt.Println(num) // 输出:100 } - 必须传值的情况 若参数仅参与计算,且不希望其被修改,则应选择值传递。这样可以确保原始数据的安全性。例如:package main import "fmt" func calculateValue(num int) int { return num * 2 } func main() { originalNum := 5 result := calculateValue(originalNum) fmt.Println(originalNum) // 输出:5 fmt.Println(result) // 输出:10 } - 可传值可传地址的情况默认传值:在大多数情况下,默认选择值传递即可。例如传递简单的结构体或基本数据类型,值传递可以避免意外修改数据,使代码逻辑更加清晰。特殊情况传地址:对于大型数据结构(如包含多个字段的用户信息结构体),或者在多个模块中频繁调用的对象,如果进行值传递会导致大量的拷贝开销,此时可以考虑传递地址。例如:package main import "fmt" type User struct { Name string Age int Address string } func modifyUser(u *User) { u.Name = "New Name" } func main() { user := User{Name: "Old Name", Age: 25, Address: "123 Main St"} modifyUser(&user) fmt.Println(user.Name) // 输出:New Name } 3. 值类型与引用类型值类型 常见的值类型包括数字类型(如 int、float、double 等)、数组、指针(虽然指针指向内存地址,但它本身是值类型)、字符串等。值类型在传递时会创建副本,对副本的修改不会影响原始数据。例如:package main import "fmt" func modifyArray(arr [3]int) { arr[0] = 100 } func main() { originalArray := [3]int{1, 2, 3} modifyArray(originalArray) fmt.Println(originalArray) // 输出:[1 2 3] } 引用类型 引用类型包括切片、集合、channel 通道、函数类型等。引用类型在传递时,实际上传递的是指向底层数据结构的指针,因此对其修改会影响原始数据。例如:package main import "fmt" func modifySlice(slice []int) { slice[0] = 100 } func main() { originalSlice := []int{1, 2, 3} modifySlice(originalSlice) fmt.Println(originalSlice) // 输出:[100 2 3] }4. 深浅拷贝浅拷贝:浅拷贝只是拷贝对象本身,对于对象中引用的数据(如切片中的数组地址)不会进行拷贝。这意味着修改拷贝后的对象可能会影响原始数据,但拷贝成本较低。例如:package main import "fmt" func shallowCopySlice(slice []int) []int { newSlice := slice newSlice[0] = 100 return newSlice } func main() { originalSlice := []int{1, 2, 3} copiedSlice := shallowCopySlice(originalSlice) fmt.Println(originalSlice) // 输出:[100 2 3] fmt.Println(copiedSlice) // 输出:[100 2 3] } 深拷贝:深拷贝不仅拷贝对象本身,还会递归地拷贝对象中引用的数据。这样可以确保修改拷贝后的对象不会影响原始数据,但拷贝成本较高。在 Go 语言中,通常需要手动实现深拷贝逻辑。5. 方法接收器(Receiver)的选择 对于方法接收器(Receiver),如果没有规范要求,建议统一使用指针类型(*T)。这样做的好处是可以兼容值类型和指针类型的调用,并且在结构有方法且可能被多个位置频繁引用时,使用指针类型可以减少数据拷贝开销。例如:package main import "fmt" type Cat struct { Name string } func (c *Cat) SetName(name string) { c.Name = name } func (c Cat) GetName() string { return c.Name } func main() { cat := Cat{Name: "Kitty"} cat.SetName("Tom") fmt.Println(cat.GetName()) // 输出:Tom // 使用指针调用方法 ptrCat := &cat ptrCat.SetName("Jerry") fmt.Println(cat.GetName()) // 输出:Jerry }
Golang的特性六(值传递与指针传递)----参数传递机制 在 Go 语言开发过程中,我们常常会面临一个抉择:在函数调用时,究竟应该选择值传递还是指针传递?这不仅关乎程序的性能,更影响着数据的安全性和一致性。go允许通过指针(有时称为引用)和值来传递参数。在这篇文章中,我们将比较两种方法,特别注意可能影响选择的不同情境。1. go中的传递本质 在 Go 语言里,只有值传递。所谓的引用传递,实际上也是传值,只不过拷贝的对象是一个地址,这个地址指向了另一个值的存储位置。所以,我们可以将问题转换为:到底该传值还是该传地址?2. 如何选择传递方法是 - 遵循项目规范 项目规范文档是我们的首要依据。如果文档中对函数参数传递方式有明确规定,那么按照文档执行即可。例如,在调用第三方 SDK 时,很多简单类型(如 int、字符串类型等)的参数传递往往遵循特定规范,可能会要求传地址,这背后是为了满足接口设计的一致性和效率需求。- 必须传地址的情况 当需要修改原始数据时,必须传递地址。如果传入值的副本,在函数内部对副本的修改将无法影响到原始数据。例如:package main import "fmt" func modifyValue(ptr *int) { *ptr = 100 } func main() { num := 50 modifyValue(&num) fmt.Println(num) // 输出:100 } - 必须传值的情况 若参数仅参与计算,且不希望其被修改,则应选择值传递。这样可以确保原始数据的安全性。例如:package main import "fmt" func calculateValue(num int) int { return num * 2 } func main() { originalNum := 5 result := calculateValue(originalNum) fmt.Println(originalNum) // 输出:5 fmt.Println(result) // 输出:10 } - 可传值可传地址的情况默认传值:在大多数情况下,默认选择值传递即可。例如传递简单的结构体或基本数据类型,值传递可以避免意外修改数据,使代码逻辑更加清晰。特殊情况传地址:对于大型数据结构(如包含多个字段的用户信息结构体),或者在多个模块中频繁调用的对象,如果进行值传递会导致大量的拷贝开销,此时可以考虑传递地址。例如:package main import "fmt" type User struct { Name string Age int Address string } func modifyUser(u *User) { u.Name = "New Name" } func main() { user := User{Name: "Old Name", Age: 25, Address: "123 Main St"} modifyUser(&user) fmt.Println(user.Name) // 输出:New Name } 3. 值类型与引用类型值类型 常见的值类型包括数字类型(如 int、float、double 等)、数组、指针(虽然指针指向内存地址,但它本身是值类型)、字符串等。值类型在传递时会创建副本,对副本的修改不会影响原始数据。例如:package main import "fmt" func modifyArray(arr [3]int) { arr[0] = 100 } func main() { originalArray := [3]int{1, 2, 3} modifyArray(originalArray) fmt.Println(originalArray) // 输出:[1 2 3] } 引用类型 引用类型包括切片、集合、channel 通道、函数类型等。引用类型在传递时,实际上传递的是指向底层数据结构的指针,因此对其修改会影响原始数据。例如:package main import "fmt" func modifySlice(slice []int) { slice[0] = 100 } func main() { originalSlice := []int{1, 2, 3} modifySlice(originalSlice) fmt.Println(originalSlice) // 输出:[100 2 3] }4. 深浅拷贝浅拷贝:浅拷贝只是拷贝对象本身,对于对象中引用的数据(如切片中的数组地址)不会进行拷贝。这意味着修改拷贝后的对象可能会影响原始数据,但拷贝成本较低。例如:package main import "fmt" func shallowCopySlice(slice []int) []int { newSlice := slice newSlice[0] = 100 return newSlice } func main() { originalSlice := []int{1, 2, 3} copiedSlice := shallowCopySlice(originalSlice) fmt.Println(originalSlice) // 输出:[100 2 3] fmt.Println(copiedSlice) // 输出:[100 2 3] } 深拷贝:深拷贝不仅拷贝对象本身,还会递归地拷贝对象中引用的数据。这样可以确保修改拷贝后的对象不会影响原始数据,但拷贝成本较高。在 Go 语言中,通常需要手动实现深拷贝逻辑。5. 方法接收器(Receiver)的选择 对于方法接收器(Receiver),如果没有规范要求,建议统一使用指针类型(*T)。这样做的好处是可以兼容值类型和指针类型的调用,并且在结构有方法且可能被多个位置频繁引用时,使用指针类型可以减少数据拷贝开销。例如:package main import "fmt" type Cat struct { Name string } func (c *Cat) SetName(name string) { c.Name = name } func (c Cat) GetName() string { return c.Name } func main() { cat := Cat{Name: "Kitty"} cat.SetName("Tom") fmt.Println(cat.GetName()) // 输出:Tom // 使用指针调用方法 ptrCat := &cat ptrCat.SetName("Jerry") fmt.Println(cat.GetName()) // 输出:Jerry }